6.1 Races
As an example of why we need locks, consider two processes
with exited children calling
wait on two different
CPUs. wait frees the child’s memory.
Thus
on each CPU, the kernel will call kfree
to free the children’s memory pages. The kernel allocator maintains a linked
list: kalloc() (kernel/kalloc.c:69) pops a
page of memory from a list of free pages, and kfree()
(kernel/kalloc.c:47) pushes a page onto the free list.
For best performance, we might hope that the kfrees of the two parent processes
would execute in parallel without either having to wait for the other,
but this would not be correct given xv6’s kfree implementation.
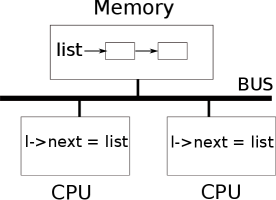
Figure 6.1 illustrates the setting in more detail: the
linked list of free pages is in memory that is shared by the two CPUs, which
manipulate the list using load and store instructions. (In
reality, the processors have caches, but conceptually
multiprocessor systems behave as if there were a single, shared memory.)
If there were no concurrent
requests, you might implement a list push operation as
follows:
1 struct element {2 int data;3 struct element *next;4 };56 struct element *list = 0;78 void9 push(int data)10 {11 struct element *l;1213 l = malloc(sizeof *l);14 l->data = data;15 l->next = list;16 list = l;17 }
This implementation is correct if executed in isolation.
However, the code is not correct if more than one
copy executes concurrently.
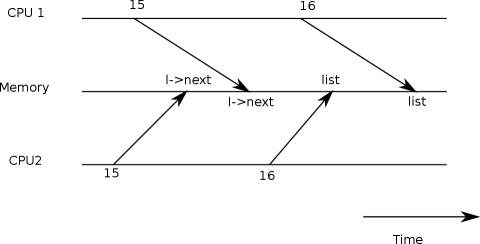
If two CPUs execute
push
at the same time,
both might execute line 15 as shown in Fig 6.1,
before either executes line 16, which results
in an incorrect outcome as illustrated by Figure 6.2.
There would then be two
list elements with
next
set to the former value of
list.
When the two assignments to
list
happen at line 16,
the second one will overwrite the first;
the element involved in the first assignment
will be lost.
The lost update at line 16 is an example of a
race.
A race is a situation in which a memory location is accessed
concurrently, and at least one access is a write.
A race is often a sign of a bug, either a lost update
(if the accesses are writes) or a read of
an incompletely-updated data structure.
The outcome of a race depends on
the machine code generated by the compiler,
the timing of the two CPUs involved,
and how their memory operations are ordered by the memory system,
which can make race-induced errors difficult to reproduce
and debug.
For example, adding print statements while debugging
push
might change the timing of the execution enough
to make the race disappear.
The usual way to avoid races is to use a lock.
Locks ensure
mutual exclusion,
so that only one CPU at a time can execute
the sensitive lines of
push;
this makes the scenario above impossible.
The correctly locked version of the above code
adds just a few lines (highlighted in yellow):
6 struct element *list = 0;7 struct lock listlock;89 void10 push(int data)11 {12 struct element *l;13 l = malloc(sizeof *l);14 l->data = data;1516 acquire(&listlock);17 l->next = list;18 list = l;19 release(&listlock);20 }
The sequence of instructions between
acquire
and
release
is often called a
critical section.
The lock is typically said to be protecting
list.
When we say that a lock protects data, we really mean
that the lock protects some collection of invariants
that apply to the data.
Invariants are properties of data structures that
are maintained across operations.
Typically, an operation’s correct behavior depends
on the invariants being true when the operation
begins. The operation may temporarily violate
the invariants but must reestablish them before
finishing.
For example, in the linked list case, the invariant is that
list
points at the first element in the list
and that each element’s
next
field points at the next element.
The implementation of
push
violates this invariant temporarily: in line 17,
l
points
to the next list element, but
list
does not point at
l
yet (reestablished at line 18).
The race we examined above
happened because a second CPU executed
code that depended on the list invariants
while they were (temporarily) violated.
Proper use of a lock ensures that only one CPU at a time
can operate on the data structure in the critical section, so that
no CPU will execute a data structure operation when the
data structure’s invariants do not hold.
You can think of a lock as serializing concurrent critical sections so that they run one at a time, and thus preserve invariants (assuming the critical sections are correct in isolation). You can also think of critical sections guarded by the same lock as being atomic with respect to each other, so that each sees only the complete set of changes from earlier critical sections, and never sees partially-completed updates.
Though useful for correctness, locks inherently limit performance. For example, if two processes call kfree concurrently, the locks will serialize the two critical sections, so that there is no benefit from running them on different CPUs. We say that multiple processes conflict if they want the same lock at the same time, or that the lock experiences contention. A major challenge in kernel design is avoidance of lock contention in pursuit of parallelism. Xv6 does little of that, but sophisticated kernels organize data structures and algorithms specifically to avoid lock contention. In the list example, a kernel may maintain a separate free list per CPU and only touch another CPU’s free list if the current CPU’s list is empty and it must steal memory from another CPU. Other use cases may require more complicated designs.
The placement of locks is also important for performance.
For example, it would be correct to move
acquire
earlier in
push,
before line 13.
But this would likely reduce performance because then the calls
to
malloc
would be serialized.
The section “Using locks” below provides some guidelines for where to insert
acquire
and
release
invocations.